Container Image
We will use the container image provided by vLLM at vllm/vllm-openai [dockerhub].Deploy vLLM OpenAI API
Let’s get started, follow these steps to create the app.1
Compute
5090
32 GiB GPU
4 CPU • 32 GiB RAM
2
Container
Set to
vLLM QwenSet to
vllm/vllm-openai:latestLeave it empty
Set to
python3 -m vllm.entrypoints.openai.api_server --port 80 --model /8scale_hf_model --gpu_memory_utilization 0.88scale_hf_model is the directory for model cache provided by 8scaleLeave it as 1 GiB
Leave it as 0
3
4
Environment
Set the following environment variables:
8SCALE_HF_MODEL=Qwen/Qwen2.5-3B
VLLM_DISABLE_COMPILE_CACHE=18SCALE_HF_MODEL env variable enables 8scale model caching and mounts the model on path /8scale_hf_model. 8Scale will automatically download the model and its part of the CACHING status for a replica.For private models or if you want to supply your own huggingface token, you can set HF_TOKEN env variable.Click Deploy App and then go to apps page and click vLLM Qwen app to get to overview page.Test vLLM API
Click playground tab. Type the following body in POST/v1/completions and hit send.
The result should look like this.
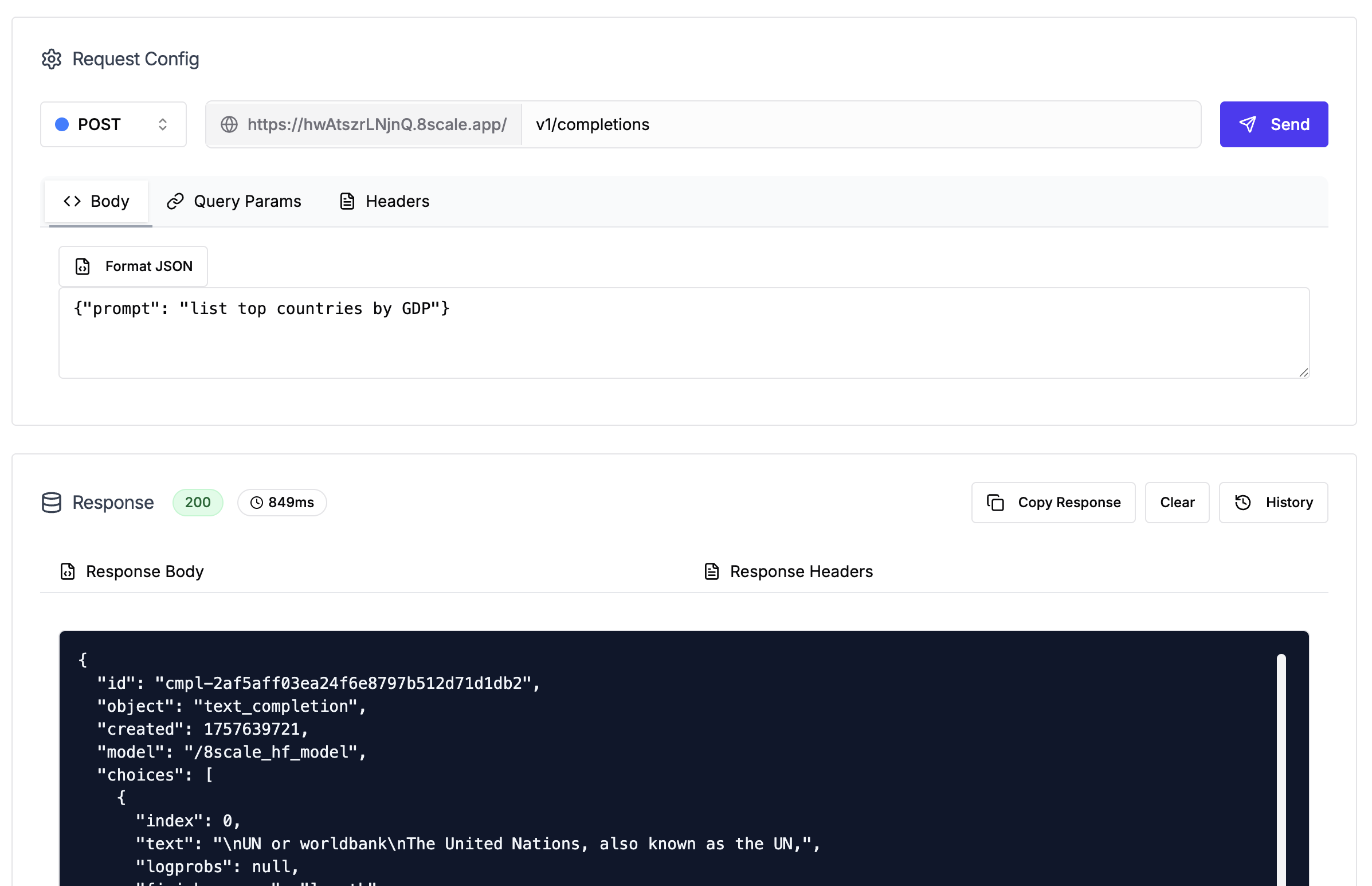
/v1/completions request.